Having data quality monitoring in place will allow you to trust the data flowing through your data platform and to take action to improve it. Data quality monitoring should be considered from both short-term and long-term perspectives. This blog post will discuss the differences and suggest guidelines for implementing data quality monitoring.
I wrote previously about data quality dimensions and how you could test these in the different zones of a data warehouse. Continuing on that subject, I will get into what to do with the test results in the short-term (operative) and long-term scopes. Measured data quality dimensions might be the same in both, but there are differences in the objectives.
Operative monitoring
The goal of operative monitoring is to catch and eliminate the recurring issues and transient errors that cause bad data quality. To achieve this goal, you need to improve your data pipelines continuously to strengthen their robustness.
Operative monitoring keeps you informed about the current status of the data warehouse and its operations. From the data quality perspective, operative monitoring identifies critical data issues and alerts your DataOps team about them. An example of a critical error could be that the flow of source data has been interrupted, and no data has been received since a given threshold period, raising a data timeliness alert.
Alerts create immediate action
Alerts keep your DataOps team on top of operative data quality monitoring efficiently. However, to ensure quick responses to critical data quality problems in your data platform, you must find a balance when assessing error criticality and creating new alert rules.
While it is easy to create new alerts, you need to remember that the data platform should only raise alerts for critical issues requiring immediate action. If there are too many false positives or alerts of unimportant issues, your DataOps team will lose interest and might miss critical errors. Unfortunately, it is common in data warehouse environments that numerous recurring alerts continuously bombard the alert channels, and no one responds to them.

Long-term monitoring
With long-term monitoring, you collect data for long-term analysis and continuous improvement of data quality on your data platform instead of reacting to daily issues critical to your operations. Long-term data quality monitoring involves defining a comprehensive testing plan for your chosen data quality dimensions and collecting the test results over time.
For example, you could be monitoring the completeness and validity of customer data loaded from an operative source system by testing if it contains all the required attribute values and if the values are in the correct format. Typically this could include checking details such as names, phone numbers, and email addresses. These can be important details, but missing them is usually not critical enough for alerting. Note that your business requirements always define the criticality of specific details!

Collect statistics for continuous improvement
All data quality issues cannot be critical enough to trigger alerts and immediate action. Also, not all issues are something that can be fixed immediately as a response to an alert, regardless of how critical they are. Rather, issues of this type would require longer-term analysis and continuous improvement.
The root causes could, for example, be in a rigid workflow in an operative system where users have found various creative workarounds to get their work done. However, fixing these issues would require a heavy manual process since they originate from business processes that produce incomplete or invalid data.
The key to success here is to acknowledge that there are issues in the data, define tests and collect data quality statistics systematically over time. Once you have statistics, it is easier to identify the significant problems and analyze their root causes. Then, you can better focus your data quality improvement efforts and measure their effectiveness.
Focusing your data quality monitoring and improvement efforts
I have sketched the following diagram as a loose framework for focusing data quality monitoring and improvement efforts. The diagram categorizes data quality issues on the axes of frequency and criticality.
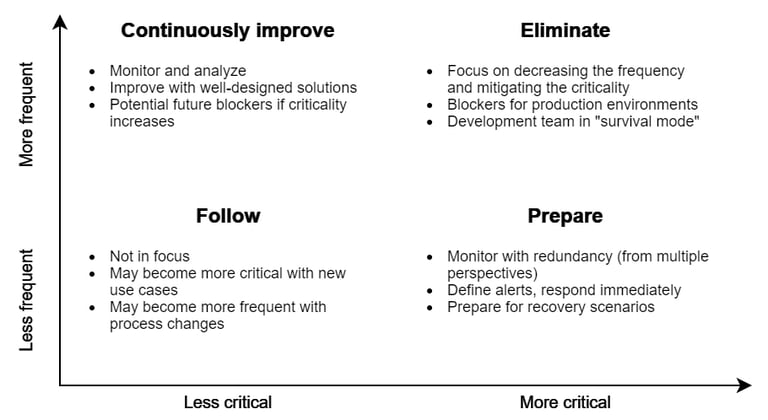
Frequent and critical - eliminate now
Data quality issues in the Eliminate category are blockers for your production environment. Since these issues are critical, you likely have alerts configured that are triggered constantly due to the high frequency. Also, the business will have a hard time trusting the data.
Continuous production incidents are a significant burden for your DataOps team, which must be in constant survival mode to fix the problems. Also, focusing on development tasks will be difficult due to constant interruptions. As a result, they might favor quick fixes over well-designed improvements creating further technical debt and more problems in the future.
Your priority should be to eliminate such issues or mitigate them by reducing the frequency, criticality, or both: a solution cannot be production-ready if constant critical data quality issues exist! That is why it is crucial to identify such blockers in the PoC or development phase and to mitigate them before moving to production.
It is quite common to see PoC-grade solutions used for production purposes because the demand for the solution is high. Also, often it can still take quite a bit of effort to achieve production readiness after the PoC phase. DataOps products such as Agile Data Engine can reduce this burden by offering the needed technical capability from day one.
Rare but critical - prepare in advance
Your DataOps team can Prepare for critical data quality issues that occur rarely. Alerts work best for this category. Alerts notify the team about an issue immediately, even before end users have detected it, and enable an immediate response. In the best case, the team can fix the problem before end users notice it. Also, when there is not a constant stream of alerts, your DataOps team will take alerts seriously.
Preparing for different recovery scenarios and having the tools, documentation, and knowledge in place will help solve problems more quickly. In addition, creating some redundancy when configuring the monitoring and alerts will make it easier to pinpoint root causes and understand the scope of the effects of the problem. It will also ensure that the platform raises alerts even when one component of the platform is down.
Whenever new issues belonging to this category are detected, evaluate if the issue is something that could reoccur and if alerts could catch it. Then, define improvements to your pipelines, monitoring, and alerts accordingly. Note that there can always be issues so random in nature that predefined alert rules cannot catch them. That is where general preparedness to recover from such incidents comes in handy.
From the long-term monitoring perspective, you could follow the frequency of this type of issue and react if it increases. Such statistics might also help monitor the availability of your data platform.
Frequent but less critical - continuously improve
Data quality issues in the Continuously improve category are common but not that critical for the business. These issues are good candidates for long-term monitoring and continuous improvement as they are not critical enough for operative alerts.
As always, seek well-designed solutions at the source of the issues. Having statistics available will help you analyze the data quality status and trends of your data platform, focus improvement efforts and monitor the effectiveness of improvements.
Note that new business cases could change the criticality of specific data sets! This type of issue might become a blocker in the future.
Rare and not critical - follow up occasionally
Data quality issues in this category are not your primary concern and, therefore, not the focus of your DataOps team. However, as noted in the previous category, criticality can increase. Also, issue frequency can increase when you change the underlying processes. Thus, issues in the Follow category may become more significant later.
Data quality monitoring with Agile Data Engine
We have seen and built various ways to manage data quality in our customer environments. The solutions range from custom business rules and mapping tables in the data warehouse load logic to implementing dedicated master data management systems. We compiled our best practices for data quality monitoring with Agile Data Engine into a simple guide.