Deliver Trusted Data Products Consistently
Elevate your data warehouse into a robust and scalable data product production line with a metadata-driven automation framework.

Metadata-driven modeling for data products
Shared design environment
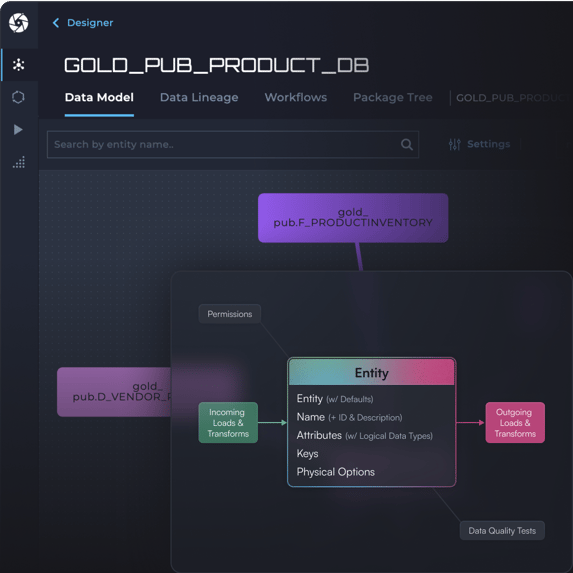
With Agile Data Engine, the data team is using a shared design environment and user interface for designing data models and transformations to foster active collaboration across users and teams. Data model and data lineage visualizations give an interactive overview to the data warehouse content.
Modular metadata framework
Agile Data Engine has innovative metadata-driven approach that treats database entities as modular building blocks. Each entity contains data model definitions, transformation logic and deployment instructions together in one object. This one-of-a-kind modular framework enables true agility in data warehousing, without sacrificing development and data governance.
Consistency, productivity and flexibility
The data product framework enables teams to work productively and consistently through standardized practices and reusable templates. Agile Data Engine retains flexibility with the freedom to implement custom SQL when required.
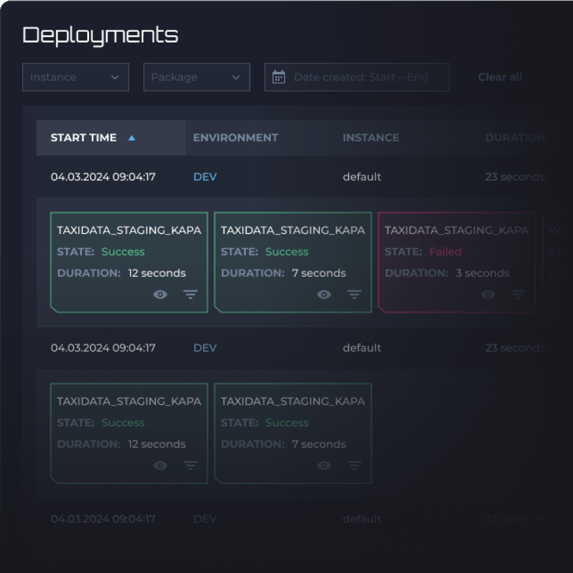
Worry-free production deployments
Automated continuous delivery pipeline
An out-of-the-box CI/CD (Continuous Integration and Deployment) eliminates the overhead of custom deployment pipelines, so data teams can focus on what truly matters—delivering value from data.
Automatic schema changes
With automated schema change management and deployment sequencing, data teams can release updates to production environments multiple times a day—without impacting data product stability.
Intelligent data workflows
Automatic generation of workflows
Agile Data Engine automatically generates optimized workflow execution paths—with proper parallelization—based on data dependencies and refresh requirements, eliminating the need for manual workflow design.
Improving load stability
This automation removes the tedious task of manually synchronizing ETL jobs with database changes, significantly reducing cloud data warehouse pipeline failures and operations costs.
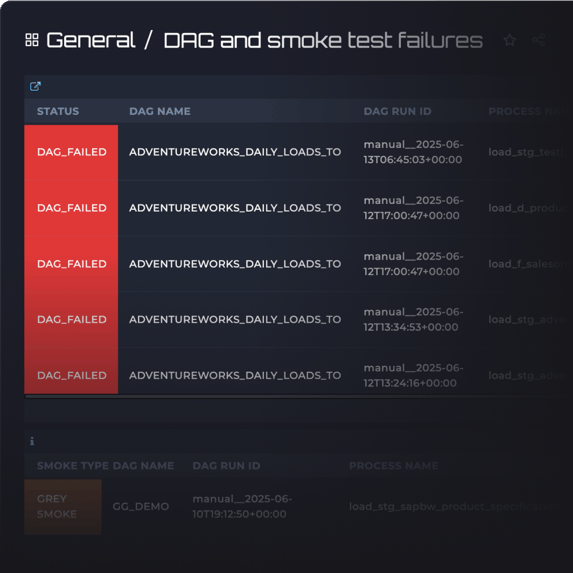
Integrated data quality testing
Continuous data quality testing
Agile Data Engine enables continuous data testing to ensure reliability and build trust. Data quality tests run directly within processing workflows, validating data as part of the load pipeline—not as separate, disconnected processes.
Early control of data correctness
Data quality tests can raise alerts or stop workflows based on severity. This helps to prevent bad data propagation and providing early warning of potential problems before affecting business decisions.