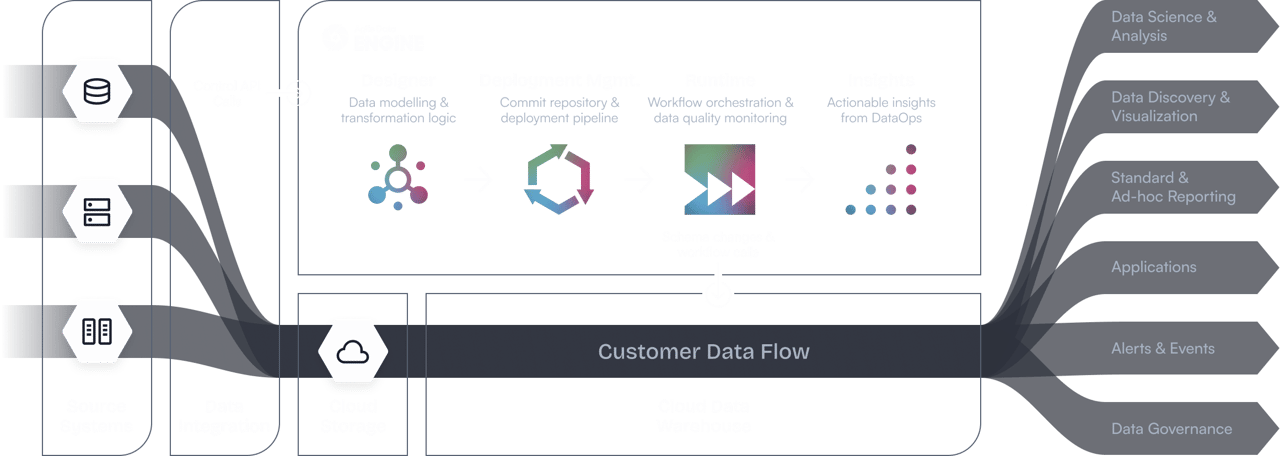
Explore how Agile Data Engine powers data teams
- 01Simplified architecture, less time on maintenance.
- 02Built-in team productivity, more value for business.
- 03Governed flexibility.
Agile Data Engine is a low-code DataOps platform for designing, deploying and operating cloud data warehouses.

Agile Data Engine transforms how enterprises build, run, and scale data warehouses and lakehouses. Turn complexity into clarity, and unscalable efforts into resilient data capability.